
Oracle Top Tips - Business Continuity

Let’s face it, Business Continuity is often one of those things that is mentioned and then forgotten in the rush of getting the next great business offering to market. But in light of Cloudflare’s recent outage, I thought it a good time to discuss the basics of Business Continuity and Disaster Recovery.
The first thing to understand, is that Business Continuity can be seen very differently by the business staff and the team actually running the systems and it is critical that both communities understand and agree on what steps to take - and when.
The nature of operational teams means that they focus on specific issues, but when looking at Business Continuity, we should plan wider than one issue - we need to plan for the loss of an application landscape or even a data centre.
Having lived through a few data centre level issues - and as we have just seen, they do happen, the cause can be something as unlikely as a stuck valve in a coolant supply system, but are more likely to happen due to human error or unforeseen software incompatibilities.
Have a plan!
Business Continuity is not just an IT matter, the teams within the business must know how to continue their roles without key systems and when the continuity event happens, you need a plan to work to. Everyone must know what to focus on to get the business running again. Here are some things to consider:
- Nominate a team to coordinate and communicate - information is gold.
- Put required teams in ‘work-around’ mode.
- Manage physical access - someone is going to attend the sites involved.
- Start the required infrastructure - Firewalls, LAN, WAN, Load Balancers and Storage networks.
- Enable remote access - get all teams online.
- Have a prioritised list of applications for recovery - resource is finite, focus is everything.
- Use a communication plan to keep stakeholders informed - document recovery stages.
- Keep Software Asset and Configuration Management (SACM) information current - recovery situations are fluid, keep records.
- When a system is reopened for use, document and communicate.
Know your acronyms:
BCP
Business Continuity Planning - How the Business will work during a major outage and how it will return to normal running. In my view, this is a must have.
BRP
Business Resumption Planning is often the department responsible for BCP.
RTO
Recovery Time Objective refers to the maximum acceptable length of time that can elapse before the lack of a business function severely impacts the organization.
MAD or MTD
Maximum Allowable Downtime or Maximum Tolerable Downtime comparable to RTO, but whereas RTO is related to a given component or a service, MAD/MTD apply at a higher level, to the entire business.
DR
Disaster Recovery. Invoking DR will often involve complete recoveries, or switching to a second site and reconfiguring applications.
IM
Incident Management. The normal way individual components or services are brought back to life. When BC or DR events are declared, the Incident Managers are often responsible for coordination and communication.
For a much wider list, see the Business Continuity Management Institute’s Wiki.
What can Oracle Database do for you?
Let’s be blunt, designing for Business Continuity costs money, so it’s good to know what your options are. Oracle can cover your needs from a simple single instance on a single site, up to a much more resilient multi site replica setup.
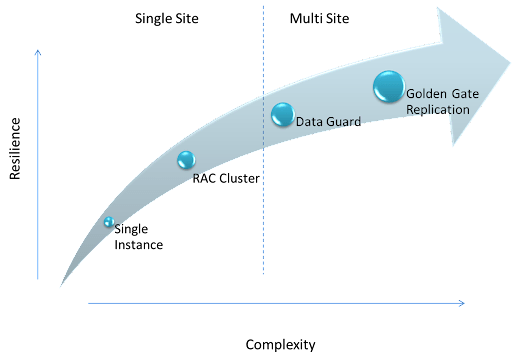
Single instances have little in the way of resilience and the SLA for the service must be carefully considered but they are great for ease of management. If your single instance sits on a VM platform, or is in the cloud then suddenly your system is much more resilient, although subject to a complete recovery in case of a disaster. When deploying on VMs, be aware of the licensing agreement you have as Oracle does not make it easy to deploy in VMs without it becoming very expensive - very quickly.
RAC Clusters are great for a single site resilient solution with a higher level SLA. In this case the database is opened on two or more nodes, and services will continue on the second node. To get the most out of a cluster, applications need to be RAC aware. Objects will be mastered by one node and updates from other nodes will generate traffic on the cluster interconnect. Too much interconnect traffic will affect performance.
Data Guard solutions allow geographical separation of physical copies of your database. Transactions can be asynchronously or synchronously applied to your standby copies depending on the availability mode selected.
- Maximum Availability - Waits for remote write acknowledgement in normal running, but will not stop the production site if there is an issue.
- Maximum Performance - The redo stream is asynchronously copied to remote sites without affecting production performance.
- Maximum Protection - Synchronous replication. A problem at a remote site will stop production.
- Fast Sync and Far Sync - To overcome synchronous performance issues caused by long distance replication, Oracle 12c introduced Fast Sync which allows acknowledgement of redo when it has been received in the remote server’s memory, and Far Sync (in its Active Data Guard licence) which introduces a specialised local instance to synchronously receive the redo stream and then forward it asynchronously to a remote site.
- Logical Standby - Although Data Guard is usually deployed as physical replicas updated via the redo stream, it can be deployed as a logical standby database which replicates database changes at a SQL level.
- Active Data Guard - Allows standby copies to be opened for reporting or used for rolling patching and application upgrade testing.
Golden Gate moves away from physical copies and goes into the world of logical replication. This allows you to define which critical time sensitive data you take to another site, cutting down the amount of data sent across your network links. Active - Active replication and data transformations are possible. With Active - Active replication, conflict detection and resolution must be set up to ensure that all copies maintain synchronisation.
Backup/Recovery vs Second Site
Having a single site has advantages from both cost and simplicity. However when faced with a disaster scenario, a complete database recovery with a roll forward will be needed. This has to be balanced against the additional cost and complexity of running replication to other sites. Having replication copies available which can be used for backups and testing upgrades, and which do not impact on production, does have significant advantages..
In a disaster - communication is key! Take for example the recent outage at Cloudflare where service recovery was slowed down by already fixed systems being ‘fixed’ again.
So remember - Have a plan, and communicate. Good luck out there.
What have you seen?
What is the strangest cause of a BC/DR situation? For me, it was a fire suppression system cutting power to the data centre when a sensor reported there was no water in the system. This was odd considering the water based system had been turned off and replaced by a gas based suppression system. It triggered anyway - because… IT happens!
